Claude Code Auto Memory: AI가 스스로 기억을 관리하는 시대

"그 설정 또 알려줘야 해?" 현업 개발자에게 들어보니 Claude Code를 쓸 때 가장 짜증나는 순간이 바로 이겁니다. 새 세션을 열 때마다 "이 프로젝트는 pnpm을 씁니다", "테스트는 vitest로 돌립니다", "커밋 메시지는 영어로 씁니다"를 반복해서 알려주는 것. CLAUDE.md에 적어놓으면 되긴 하지만, 그걸 적는 것도 결국 사람 몫이었습니다.
2026년 2월 27일, Anthropic이 Claude Code 2.1.59 버전에 Auto Memory 기능을 추가했습니다. Claude가 작업 중에 배운 것을 스스로 메모하고, 다음 세션에서 그 메모를 읽어서 활용합니다. 사람이 일일이 알려줄 필요가 없어진 겁니다.
왜 지금 나왔는지, 어떻게 작동하는지, 어떻게 쓰면 되는지 정리해 봤습니다.
프롬프트 엔지니어링에서 컨텍스트 엔지니어링으로
Auto Memory를 이해하려면 배경부터 짚어야 합니다. AI를 잘 쓰는 방법 자체가 바뀌고 있거든요.
2023년에는 프롬프트 엔지니어링이 전부였습니다. "어떻게 질문하느냐"가 결과를 좌우했습니다. 그런데 2025년부터 분위기가 달라졌습니다. 모델 성능이 올라가면서 "어떤 정보를 모델에게 주느냐", 즉 컨텍스트 관리가 더 중요해진 겁니다.
Gartner는 2026년 보고서에서 컨텍스트 엔지니어링을 "엔터프라이즈 AI 인프라의 기반 요소"로 정의했습니다. LangChain의 2025 State of Agent Engineering 보고서도 같은 이야기를 합니다. 57%의 조직이 AI 에이전트를 프로덕션에 배포했지만, 32%가 품질 문제를 최대 장벽으로 꼽았습니다. 대부분의 실패 원인은 LLM 능력 부족이 아니라 컨텍스트 관리 미흡이었습니다.
프롬프트는 "이번에 무엇을 해달라"는 지시입니다. 컨텍스트는 "네가 알아야 할 모든 배경 정보"입니다. 프로젝트 구조, 코딩 규칙, 지난 세션에서 해결한 버그, 팀 워크플로우 같은 것들이죠. 양이 아니라 질이 다른 영역입니다.
Anthropic의 엔지니어링 블로그는 이 문제를 "제한된 주의 예산"이라는 프레임으로 설명합니다. 트랜스포머 아키텍처에서 n개 토큰이 입력되면 토큰 수의 제곱에 비례하는 연산을 처리해야 합니다. 토큰이 늘어날수록 모델의 주의력이 분산됩니다. 학습 데이터에서도 짧은 시퀀스가 훨씬 많기 때문에 긴 컨텍스트를 처리하는 능력은 구조적으로 제한됩니다. 그래서 핵심은 "가장 작은 고신호 토큰 집합을 찾아서 원하는 결과가 나올 확률을 최대화"하는 것입니다.
Auto Memory는 이 컨텍스트 엔지니어링을 AI 스스로 하게 만든 기능입니다.
Auto Memory의 기술적 구조
두 종류의 기억
Claude Code에는 이제 두 종류의 기억이 있습니다.
하나는 CLAUDE.md 파일입니다. 사용자가 직접 작성하는 지침서로, "TypeScript를 쓴다", "함수명은 camelCase" 같은 규칙을 적어둡니다. Git으로 버전 관리하고 팀원과 공유할 수 있고요.
다른 하나가 Auto Memory입니다. Claude가 작업하면서 스스로 쓰는 메모인데, "빌드 명령은 pnpm build", "JWT 토큰 검증은 src/utils/auth.ts" 같은 내용을 알아서 기록합니다. 로컬에만 저장되고 Git에는 올라가지 않습니다.
비유하면 CLAUDE.md는 회사의 개발 가이드라인이고, Auto Memory는 개발자 개인의 업무 노트입니다. 가이드라인은 팀 전체가 공유하지만 업무 노트는 각자 관리합니다.
메모리 계층 구조
Anthropic은 Claude Code의 메모리를 6단계 계층으로 설계했습니다.
가장 위에 Managed Policy가 있습니다. IT팀이 조직 전체에 배포하는 전사 규칙이죠. macOS에서는 /Library/Application Support/ClaudeCode/CLAUDE.md, Linux에서는 /etc/claude-code/CLAUDE.md에 위치합니다.
그 아래 Project Memory는 프로젝트 루트의 ./CLAUDE.md 또는 ./.claude/CLAUDE.md에 놓이고, 팀원과 소스 관리를 통해 공유합니다.
Project Rules는 ./.claude/rules/*.md 경로에 모듈별로 분리된 규칙 파일입니다. testing.md, api-design.md처럼 주제별로 나누어 관리할 수 있습니다. YAML 프론트매터의 paths 필드로 특정 파일에만 적용되는 조건부 규칙도 만들 수 있습니다.
User Memory는 ~/.claude/CLAUDE.md에 위치하는 개인 전역 설정으로, 모든 프로젝트에 적용됩니다.
Project Memory (local)는 ./CLAUDE.local.md로 개인의 프로젝트별 설정입니다. 자동으로 .gitignore에 추가되어 Git에 올라가지 않습니다.
마지막이 Auto Memory입니다. ~/.claude/projects/<project>/memory/에 위치하며, Claude가 자동으로 관리하는 학습 메모입니다.
구체적인 설정이 넓은 설정보다 우선합니다.
다음 그림은 Claude Code의 6단계 메모리 계층 구조를 보여줍니다.

가장 아래의 Managed Policy가 조직 전체에 적용되는 가장 넓은 범위이고, 위로 갈수록 범위가 좁아지면서 우선순위가 높아집니다. 맨 위의 Auto Memory는 개발자 개인의 로컬 환경에만 존재하지만 가장 구체적인 설정이므로 우선 적용됩니다.
MEMORY.md의 동작 방식
Auto Memory의 핵심 파일은 MEMORY.md입니다. 이 파일의 구조를 살펴보면 Anthropic의 설계 의도가 보입니다.
~/.claude/projects/<project>/memory/ MEMORY.md # 인덱스 파일, 매 세션 로드 (200줄 제한) debugging.md # 디버깅 패턴 상세 노트 api-conventions.md # API 설계 결정사항 ... # Claude가 필요에 따라 생성하는 토픽 파일
MEMORY.md의 처음 200줄만 매 세션 시작 시 Claude의 시스템 프롬프트에 로드됩니다. 200줄을 넘는 내용은 자동으로 로드되지 않습니다. Claude는 이 제한을 알고 있어서 상세한 내용은 별도 토픽 파일로 분리합니다.
토픽 파일은 시작 시 로드되지 않습니다. Claude가 관련 작업을 할 때 필요하면 직접 읽는, 일종의 Just-in-time 로딩입니다.
<project> 경로는 Git 저장소 루트에서 파생됩니다. 같은 저장소 내 모든 하위 디렉토리는 하나의 Auto Memory 디렉토리를 공유합니다. 단, Git worktree는 별도의 메모리 디렉토리를 가집니다.
200줄 제한의 의미
200줄 제한은 단순한 용량 제약이 아닙니다. Anthropic이 의도적으로 설계한 것입니다.
Anthropic의 엔지니어링 블로그에서 말하는 "가장 작은 고신호 토큰 집합"의 원칙을 MEMORY.md에 그대로 적용한 겁니다. 200줄이면 대략 300-400개 토큰입니다. 매 세션 시스템 프롬프트에 추가되는 오버헤드치고는 합리적인 수준입니다.
200줄 제한이 Auto Memory 전체의 제한은 아닙니다. MEMORY.md는 인덱스 역할만 하거든요. 실제 상세 내용은 토픽 파일에 저장되고, Claude는 필요할 때만 읽습니다. 파일 시스템 자체가 외부 메모리 저장소 역할을 하는 셈입니다.
이 구조는 Anthropic이 블로그에서 설명한 "구조화된 노트 작성" 패턴과 정확히 일치합니다. 에이전트가 컨텍스트 윈도우 외부에 지속적으로 메모를 저장하고, 나중에 필요할 때 검색하는 방식입니다.
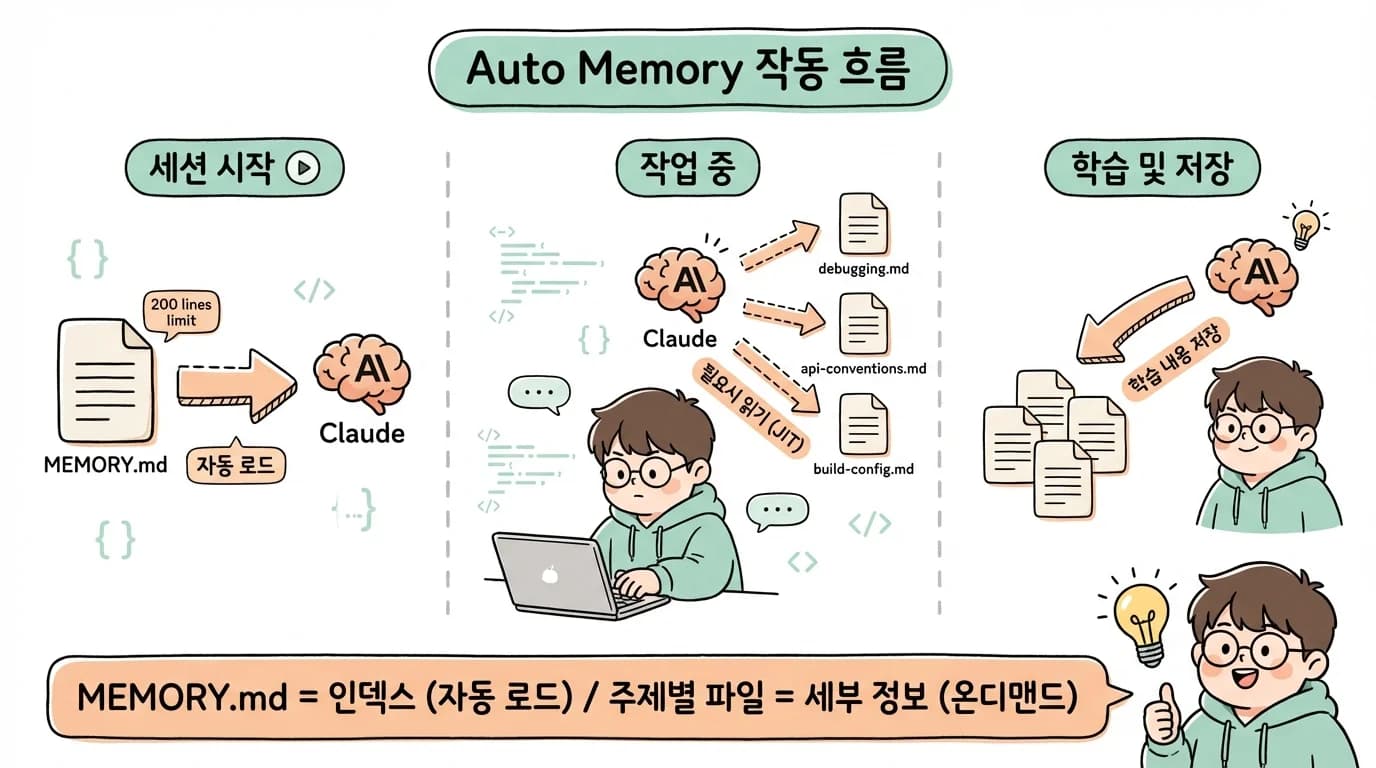
다음 그림은 Auto Memory의 세 단계 동작 흐름을 보여줍니다.

세션이 시작되면 MEMORY.md의 처음 200줄이 자동으로 로드됩니다. 작업 중에는 debugging.md, api-conventions.md 같은 토픽 파일을 필요할 때만 읽습니다. 새로운 패턴이나 지식을 발견하면 MEMORY.md를 업데이트하거나 새 토픽 파일을 생성합니다.
CLAUDE.md와 Auto Memory, 같이 써야 하는 이유
이 두 메모리 시스템은 같이 써야 제대로 작동합니다.
CLAUDE.md는 지침입니다. 사람이 AI에게 "넌 이렇게 해야 해"라고 적어두는 겁니다. 코딩 규칙, 아키텍처 결정, 워크플로우 같은 안정적이고 공유 가능한 정보를 담고요.
Auto Memory는 학습 노트입니다. AI가 작업하면서 "이건 기억해둬야겠다" 싶은 걸 스스로 적는 겁니다. 빌드 명령어, 자주 발생하는 에러 패턴, 파일 간 의존 관계 같은 실무 지식이 여기에 쌓입니다.
실전에서 어떻게 다른지 예를 들어보겠습니다.
CLAUDE.md에는 이런 내용이 적합합니다.
# 프로젝트 규칙 - TypeScript strict 모드 사용 - 함수명은 camelCase, 컴포넌트명은 PascalCase - API 응답은 반드시 zod 스키마로 검증 - 테스트 커버리지 80% 이상 유지
Auto Memory에는 Claude가 이런 내용을 스스로 적습니다.
# 빌드/테스트 - 빌드: pnpm build (turbo 사용, 캐시 ~/.turbo) - 테스트: pnpm test (vitest, --reporter=verbose 시 상세 출력) - E2E: pnpm test:e2e (playwright, 반드시 dev 서버 먼저 실행) # 디버깅 인사이트 - prisma migrate 실패 시 대부분 .env의 DATABASE_URL 문제 - Next.js 13+ 서버 컴포넌트에서 useState 사용하면 에러 발생 -> "use client" 추가 또는 클라이언트 컴포넌트로 분리 # 아키텍처 - 인증: src/lib/auth.ts (NextAuth v5) - DB: src/lib/prisma.ts (싱글턴 패턴) - API 라우트: src/app/api/ (App Router)
CLAUDE.md는 "규칙"이고 Auto Memory는 "지식"입니다. 규칙은 사람이 정하고, 지식은 AI가 일하면서 쌓습니다.
실전 활용 가이드
기본 설정
Auto Memory는 기본으로 활성화되어 있습니다. 별도 설정 없이 바로 작동합니다.
토글은 /memory 명령으로 할 수 있습니다. 이 명령을 실행하면 메모리 파일 선택기가 열리고, Auto Memory 활성화/비활성화 토글도 함께 나타납니다.
프로젝트 단위로 비활성화하려면 .claude/settings.json에 다음을 추가합니다.
{ "autoMemoryEnabled": false }
사용자 단위로 전체 비활성화하려면 ~/.claude/settings.json에 같은 설정을 추가합니다.
CI/CD 환경에서는 환경 변수로 강제 제어할 수 있습니다.
# 강제 비활성화 export CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 # 강제 활성화 export CLAUDE_CODE_DISABLE_AUTO_MEMORY=0
이 환경 변수는 /memory 토글이나 settings.json 설정보다 우선합니다.
Claude에게 직접 기억을 요청하는 방법
Auto Memory는 Claude가 알아서 기록하기도 하지만, 직접 요청할 수도 있습니다. 자연어로 말하면 됩니다.
"이 프로젝트에서는 항상 pnpm을 쓴다고 기억해" "API 테스트에 로컬 Redis 인스턴스가 필요하다는 걸 메모리에 저장해" "다음 세션에서도 기억할 수 있게, 이 디버깅 방법을 저장해"
반대로 잘못된 기억을 삭제하도록 요청할 수도 있습니다.
"npm 관련 메모리를 지워줘, 이 프로젝트에서는 yarn을 사용해"
MEMORY.md를 인덱스로 활용하기
200줄 제한을 잘 활용하는 방법은 MEMORY.md를 인덱스로 쓰는 겁니다. MEMORY.md에는 요약과 참조만 두고, 상세 내용은 토픽 파일로 분리합니다.
# 프로젝트 메모리 ## 빌드/배포 - 빌드: pnpm build, 배포: vercel - 상세 빌드 설정은 build-config.md 참조 ## 자주 발생하는 문제 - Prisma 마이그레이션 이슈 -> debugging.md 참조 - Next.js 서버/클라이언트 컴포넌트 혼동 -> architecture.md 참조 ## API 설계 패턴 - REST 엔드포인트 명명 규칙 -> api-conventions.md 참조
이렇게 하면 200줄 안에 프로젝트 전체의 중요 정보를 인덱싱할 수 있고, Claude는 필요할 때 토픽 파일을 직접 읽어서 상세 내용을 참조합니다.
메모리 검색 방법
Claude는 메모리 디렉토리 내 파일을 Grep이나 Read 도구로 검색합니다. 메모리 디렉토리 경로는 ~/.claude/projects/<project>/memory/입니다. 세션 트랜스크립트 로그(.jsonl 파일)도 검색할 수 있지만, 파일이 크고 느리기 때문에 최후의 수단으로만 사용합니다.
실전에서 만나는 문제와 대응법
Auto Memory를 실제로 쓰다 보면 부딪히는 상황이 있습니다.
가장 흔한 문제는 오래된 기억입니다. 프로젝트가 pnpm에서 bun으로 전환했는데, Claude가 여전히 pnpm build를 실행하는 식입니다. 이때는 자연어로 "pnpm 관련 메모리를 지우고, 이 프로젝트는 bun을 쓴다고 기억해"라고 요청하면 됩니다. 더 확실한 방법은 ~/.claude/projects/<project>/memory/MEMORY.md를 직접 열어서 해당 내용을 수정하거나 삭제하는 것입니다.
프로젝트 구조가 크게 바뀌었을 때는 메모리 디렉토리를 통째로 초기화할 수 있습니다. ~/.claude/projects/<project>/memory/ 디렉토리의 파일을 삭제하면 됩니다. Claude가 다시 작업하면서 새 구조에 맞는 메모리를 자동으로 쌓습니다.
브랜치 간 메모리 혼재도 주의해야 합니다. Auto Memory는 Git 저장소 루트 기준으로 하나의 디렉토리를 공유합니다. main 브랜치의 구조와 feature 브랜치의 구조가 다르면 Claude가 혼동할 수 있습니다. Git worktree를 사용하면 별도의 메모리 디렉토리가 할당되므로 이 문제를 피할 수 있습니다.
팀 협업에서 정보 차이가 생긴다는 점도 알아두어야 합니다. CLAUDE.md는 팀이 공유하지만 Auto Memory는 각자 로컬에만 있습니다. 같은 프로젝트에서 팀원마다 Claude가 다른 맥락을 가지게 됩니다. 중요한 발견사항은 Auto Memory에 맡기지 말고 CLAUDE.md나 프로젝트 문서에 명시적으로 기록하는 습관이 필요합니다.
컨텍스트 관리의 더 넓은 그림: RAG, Observational Memory, 그리고 Auto Memory
Auto Memory가 풀려는 문제를 이해하려면 AI 메모리 관리 기술의 흐름을 봐야 합니다.
RAG는 2023년부터 AI의 기억 문제를 풀기 위한 대표 기술이었습니다. 외부 데이터베이스에 정보를 저장하고 관련 내용을 검색해서 프롬프트에 주입하는 방식입니다. 개념은 명쾌하지만 실전에서는 만만치 않습니다. 검색 정확도, 청크 크기, 임베딩 품질, 리랭킹 전략 등 튜닝할 것이 많습니다. 특히 Claude Code처럼 범용 도구에서는 사용자마다 프로젝트 구조와 워크플로우가 전혀 달라서 범용 RAG 파이프라인으로 대응하기 어렵습니다.
VentureBeat가 보도한 Observational Memory라는 접근법도 있습니다. Observer와 Reflector라는 두 백그라운드 에이전트가 대화 히스토리를 날짜별 관찰 로그로 압축합니다. 에이전트 비용을 10배 절감하면서 롱 컨텍스트 벤치마크에서 RAG를 능가했다는 결과가 있습니다.
Mem0는 대화에서 핵심 정보를 동적으로 추출, 통합, 검색하는 아키텍처입니다. 선택적 검색으로 P95 지연 시간은 91%, 토큰 사용량은 90%까지 줄였습니다.
Claude Code의 Auto Memory는 이런 복잡한 아키텍처 대신 단순하지만 실용적인 접근을 택했습니다. 파일 시스템을 외부 메모리로 쓰고, 마크다운 파일에 구조화된 노트를 작성하고, 필요할 때 파일을 읽는 것입니다. RAG의 벡터 검색도 없고, 임베딩 파이프라인도 없습니다. 그냥 텍스트 파일입니다.
이 단순함이 오히려 장점입니다. 사용자가 메모리 파일을 직접 열어서 읽고, 수정하고, 삭제할 수 있습니다. 디버깅도 쉽습니다. Claude가 이상한 동작을 하면 MEMORY.md를 열어보면 됩니다. 복잡한 벡터 DB의 내용물을 들여다보는 것과는 차원이 다릅니다.
물론 트레이드오프가 있습니다. 파일 시스템 기반 텍스트 검색은 의미론적 유사성 검색이 불가능합니다. "인증 관련 이슈"를 찾으려면 "auth", "인증", "JWT", "토큰" 등 키워드를 정확히 알아야 합니다. 프로젝트가 커져서 메모리 파일이 수십 개가 되면 grep 검색만으로는 관련 정보를 빠르게 찾기 어려울 수 있습니다. Auto Memory는 개인 개발자 도구에 최적화된 접근이고, 대규모 조직의 지식 관리에는 RAG 기반 접근이 여전히 필요한 영역이 있습니다.
Anthropic 엔지니어링 블로그에서 Claude Code의 접근법을 "하이브리드 전략"이라고 설명하는 부분이 있습니다. CLAUDE.md 같은 파일은 사전에 컨텍스트에 로드하고, 추가 탐색은 glob, grep 같은 프리미티브로 런타임에 동적 수행합니다. Auto Memory는 이 하이브리드 전략의 자연스러운 확장입니다. 매 세션 200줄의 인덱스를 사전 로드하고, 상세 내용은 필요할 때 읽는 것입니다.
Auto Memory가 기억하지 않는 것
Auto Memory의 설계 원칙에는 "무엇을 기억할지"만큼 "무엇을 기억하지 않을지"도 중요합니다.
Anthropic의 공식 가이드라인에 따르면 다음은 저장하지 않습니다.
세션별 컨텍스트는 남기지 않습니다. 현재 작업 세부사항이나 임시 상태는 세션이 끝나면 사라져야 할 정보니까요.
불완전한 정보도 기록하지 않습니다. 파일 하나 읽고 내린 추측이나 검증 안 된 결론은 프로젝트 문서와 대조해서 확인될 때까지 저장하지 않습니다.
CLAUDE.md에 이미 있는 내용을 또 적지도 않습니다. 중복은 토큰 낭비입니다.
아무거나 다 기억하는 게 아니라, 기억할 가치가 있는 것만 골라서 저장하는 셈입니다.
한 가지 주의할 점은 보안입니다. Auto Memory는 프로젝트의 파일 구조, 빌드 명령어, 디버깅 패턴, 아키텍처 정보를 ~/.claude/projects/ 하위에 평문 마크다운 파일로 저장합니다. 공유 개발 서버에서 다른 사용자가 이 디렉토리를 읽으면 프로젝트의 내부 구조가 노출될 수 있습니다. Anthropic은 현재 Auto Memory에 별도의 민감 정보 필터링 메커니즘을 명시하고 있지 않습니다. 따라서 엔터프라이즈 환경에서는 홈 디렉토리 퍼미션을 적절히 설정하고, 필요하면 CI/CD 환경에서 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1로 비활성화하는 것이 안전합니다.
CLAUDE.md의 임포트 기능: 또 다른 메모리 확장
Auto Memory와 함께 알아둘 기능이 CLAUDE.md의 임포트 기능입니다. @path/to/file 문법으로 외부 파일을 CLAUDE.md에 임포트할 수 있습니다.
프로젝트 개요는 @README.md를 참고하세요. npm 명령은 @package.json을 확인하세요. # 추가 지침 - Git 워크플로우 @docs/git-instructions.md
상대 경로와 절대 경로 모두 지원합니다. 상대 경로는 임포트를 포함하는 파일 기준으로 해석됩니다. 재귀적 임포트도 가능하며 최대 5단계까지 지원합니다.
프로젝트에서 처음 외부 임포트를 만나면 승인 창이 나타납니다. 한 번 승인하면 이후에는 자동으로 로드됩니다.
여러 Git worktree를 사용하는 경우 CLAUDE.local.md는 하나의 worktree에만 존재하므로, 홈 디렉토리 임포트를 사용하면 모든 worktree에서 같은 개인 설정을 공유할 수 있습니다.
# 개인 설정 - @~/.claude/my-project-instructions.md
기존 메모리 관리 스킬과의 관계
개발 커뮤니티에서 흥미로운 논의가 있습니다. Auto Memory 이전부터 세션 랩업 스킬을 만들어서 사용하던 개발자들이 있었습니다. 세션을 마무리할 때 회의록처럼 배운 것을 정리하고, 사람이 배운 것과 AI가 배운 것을 분리해서 기록하는 방식입니다.
Auto Memory는 이런 수동 메모리 관리의 "AI가 배운 것" 부분을 자동화합니다. 하지만 "사람이 배운 것"은 여전히 Auto Memory가 처리하지 못합니다. 세션에서 개발자 자신이 깨달은 인사이트, 의사결정의 배경, 향후 작업 방향 같은 것은 별도로 관리해야 합니다.
AI의 학습은 Auto Memory가 처리하고, 사람의 학습은 별도 스킬이나 문서로 관리하는 식으로 역할을 나누면 됩니다.
마무리: 기억하는 도구와 기억하게 하는 도구
개발 도구의 역사를 보면, "개발자가 기억해야 할 것"을 도구가 대신해주는 장면이 반복됩니다. IDE 자동 완성이 API 시그니처 암기를 덜어줬고, Git이 수동 백업에서 해방시켜 줬습니다.
Auto Memory도 같은 흐름에 있는데, 한 가지 다른 점이 있습니다. 기존 도구는 개발자가 "무엇을 기억할지" 설정해야 했습니다. Git은 커밋을 해야 기록되고, CLAUDE.md도 사람이 적어야 합니다. Auto Memory는 AI가 뭘 기억할지를 스스로 판단합니다.
한계는 분명합니다. 200줄 제한, 프로젝트 단위로만 작동, 팀 간 공유 불가. 자연스럽게 드는 생각은 이겁니다. 팀원 A의 Claude가 발견한 디버깅 패턴을 팀원 B의 Claude도 알고 있다면? 지식 공유 방식이 근본적으로 달라질 수 있습니다. AI가 기억을 알아서 관리하기 시작하면, 사람이 수동으로 쓰는 CLAUDE.md의 비중은 점점 줄어들 수도 있고요.
사람이 하던 컨텍스트 관리를 AI가 분담하기 시작한 기능입니다. 크로스 프로젝트 메모리나 팀 공유 메모리 같은 확장이 언제 나올지는 모르지만, 방향은 정해졌습니다. 직접 써보면서 Auto Memory가 뭘 기억하고 뭘 놓치는지 지켜보는 게 이 도구에 익숙해지는 가장 빠른 길입니다.
참고 자료
- Anthropic, "Manage Claude's memory", Claude Code Documentation, https://code.claude.com/docs/en/memory
- Anthropic, "Effective context engineering for AI agents", Engineering Blog, https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic, Claude Code CHANGELOG.md, GitHub, https://github.com/anthropics/claude-code/blob/main/CHANGELOG.md
- Gartner, "Context engineering: Why it's Replacing Prompt Engineering for Enterprise AI Success", 2026
- LangChain, "2025 State of Agent Engineering Report"
- VentureBeat, "Observational memory cuts AI agent costs 10x and outscores RAG on long-context benchmarks"
- Mem0, "Building Production-Ready AI Agents with Scalable Long-Term Memory", arXiv




댓글
댓글을 작성하려면 이 필요합니다.